- You are here:
- Home »
- HA-Cluster
Tag Archives for " HA-Cluster "
VMware ESXi – Isolationsadresse des vSphere HA Cluster ändern

Die Hochverfügbarkeitsfunktion (HA) in vSphere bedient sich der Isolationsadresse als eine Art „Witness“ bzw. „Zeugen“. Sollte ein Mitglied eines HA-Clusters nicht mehr mit einem anderen kommunizieren können, dient die Isolationsadresse dazu zu ermitteln, ob das Problem am betroffenen Mitglied selbst liegt oder am nicht erreichbaren Host.
Standardmäßig wird die Isolationsadresse mit dem konfigurierten Standardgateway vorbelegt. Wenn jedoch die Isolationsadresse angepasst werden soll, sind einige Einträge in den erweiterten Optionen des HA-Clusters erforderlich.
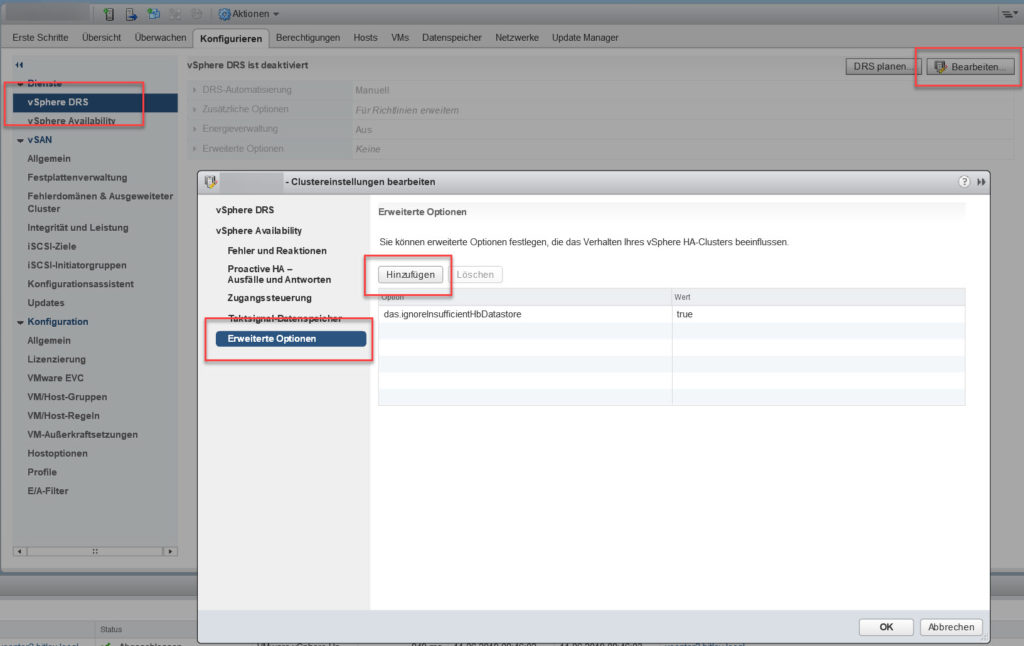
Um die Isolationsadresse zu ändern, müssen die folgenden Einträge über die Schaltfläche „Hinzufügen“ ergänzt werden:
- das.isolationaddress1: IP-Adresse
- das.isolationaddress2: IP-Adresse
- das.usedefaultisolationaddress: false
Durch den Eintrag „das.usedefaultisolationaddress“ wird der HA-Cluster angewiesen, nicht länger die Standardisolationsadresse abzufragen.
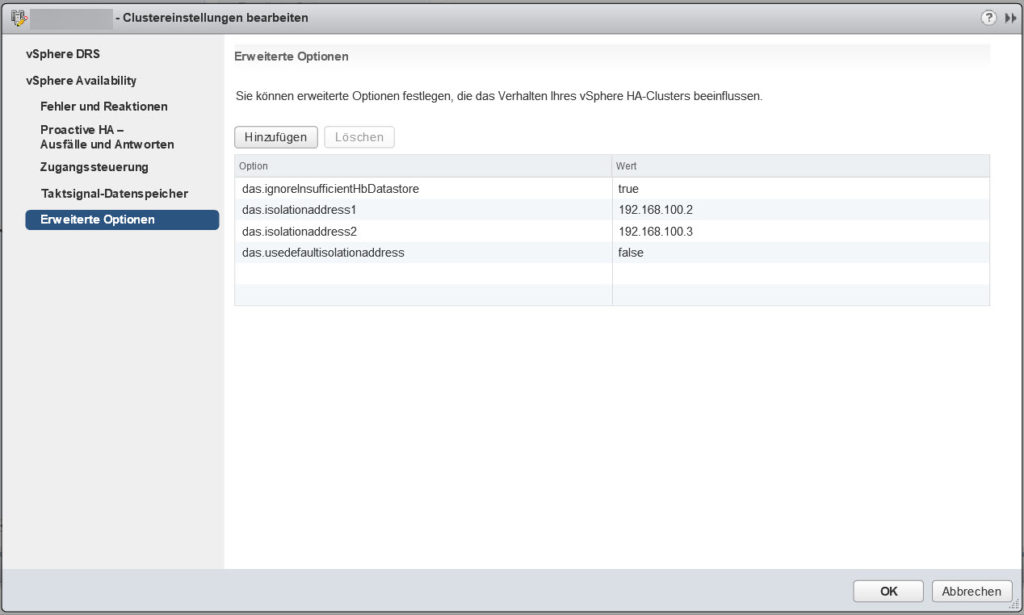
Allerdings sollte nun mindestens eine Alternativ-Adresse angegeben werden. Diese Adresse sollte von einem physischen Server stammen, der kontinuierlich erreichbar ist. Ein virtueller Server, der auf einem der Hosts im HA-Cluster gehostet wird, ist in diesem Fall nicht sinnvoll.
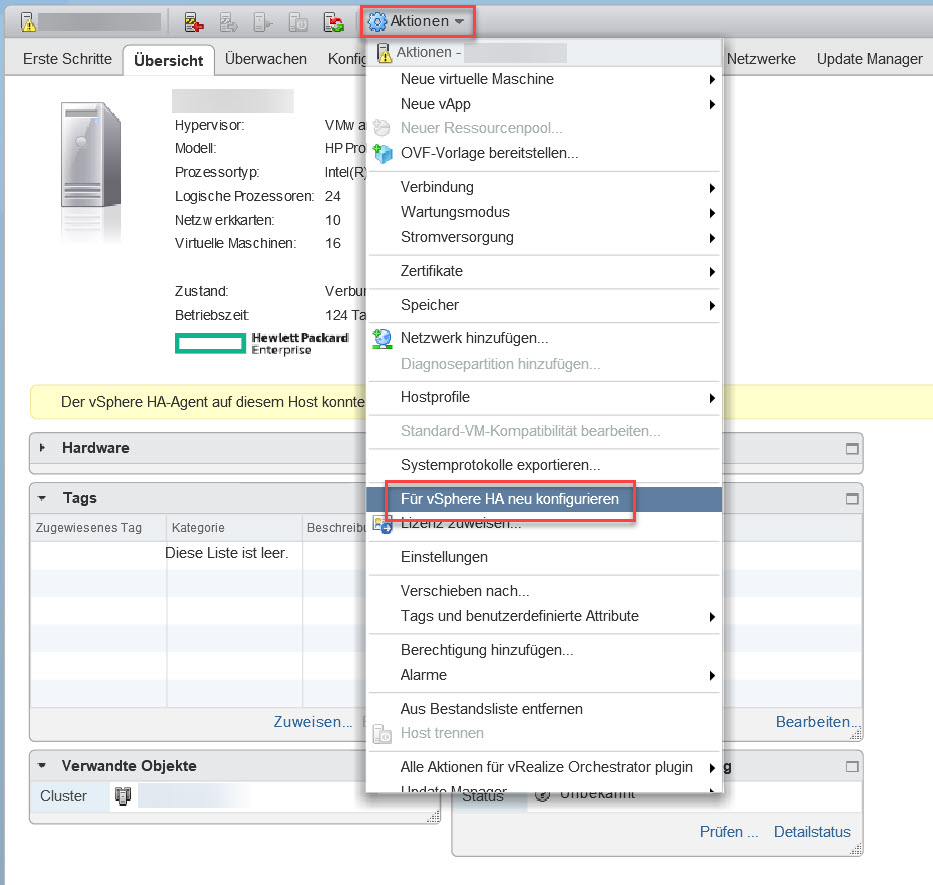
Sobald die Einträge im HA-Cluster hinzugefügt wurden, müssen die Konfigurationen auf jedem Host übernommen werden. Hierfür wählt man über das Aktionen-Menü den Punkt „Für vSphere HA neu konfigurieren“ aus.
Dadurch werden die Änderungen auf alle beteiligten Hosts angewendet, was entscheidend ist, um sicherzustellen, dass das HA-Cluster einwandfrei funktioniert und die Hochverfügbarkeit der virtuellen Maschinen gewährleistet ist. Diese sorgfältige Vorgehensweise ist von wesentlicher Bedeutung für die Stabilität und Leistungsfähigkeit des Clusters und somit für die Geschäftskontinuität.
Sophos / Astaro UTM 220 – Zeroconf failed, Permission Denied beim Aufbau eines HA-Clusters

Nachdem wir den Aufbau eines Hochverfügbarkeitsclusters mit zwei UTM 220 von Sophos / Astaro begonnen hatten, stießen wir auf einige Probleme, die es wert sind, hier ausführlicher dokumentiert zu werden.
Zunächst wurde der Cluster gemäß den folgenden Schritten eingerichtet:
- Eine bereits funktionierende UTM (mit einem aktuellen Backup) war bereits im Einsatz.
- Die zweite, neue UTM wurde vorerst nur über den HA-Port mit der ersten UTM verbunden (im Standard ETH3).
- Nach dem Anschalten der neuen UTM erschien unmittelbar darauf eine Meldung auf dem Display, die besagte:
„Trying zeroconf. Zeroconf failed, Permission denied.“
Kurz darauf fuhr die UTM unerwartet herunter.
Im HA-Live-Protokoll der UTM wurde der folgende Eintrag generiert:
„Autojoin of 198.xxx.xxx.xxx denied“.
Bei einer gründlichen Überprüfung der Konfiguration in der UTM stellte sich heraus, dass unter „Hochverfügbarkeit -> Konfiguration -> Erweitert“ kein Haken bei „Automatische Konfiguration neuer Geräte aktivieren“ gesetzt war.
Um das Problem zu beheben, wurde dieser Haken gesetzt, und die neue UTM wurde erneut eingeschaltet. Dieses Mal begann sie erfolgreich mit der Synchronisierung und schloss diesen Vorgang ohne Probleme ab.
In der Statusanzeige waren nun zwei UTMs im Status „Active“ sichtbar, wobei eine als Master und die andere als Slave fungierte.
Um die Konfiguration weiter zu verfeinern und die Stabilität des Clusters zu verbessern, wurden zusätzliche Maßnahmen ergriffen:
- Unter „Konfiguration -> Hochverfügbarkeitsstatus“ wurde der Betriebsmodus auf „Hot-Standby (aktiv-passiv)“ geändert.
- Ein Haken wurde bei „Knoten während eines Up2Date zurückhalten“ gesetzt, um sicherzustellen, dass keine unerwarteten Aktualisierungen den Betrieb stören.
- Zudem wurde ein bestimmter Knoten als „Bevorzugter Master“ festgelegt, um sicherzustellen, dass die UTM nicht willkürlich zwischen den beiden Knoten umschaltet.
Diese zusätzlichen Konfigurationsschritte wurden unternommen, um eine zuverlässige und robuste Hochverfügbarkeitslösung für das Netzwerk zu gewährleisten. Nach deren Implementierung waren die UTMs erfolgreich in Betrieb und sorgten für eine kontinuierliche Verfügbarkeit der Netzwerkdienste.